Wikipedia contains a wide variety of data, including article contents and metadata such as pageviews, clickstreams, links, backlinks, edits, and revision histories. Pageviews represent the total number of clicks for a specific Wikipedia article. Data on pageviews can be accessed via different channels. First, an interactive tool offers summary data, enabling users to compare the popularity of various search items over a specified period. For data scientists, it is more useful to be able to access data in an automated fashion and integration the data collection process into the coding workflow. To that end, a second access option is more attractive: Wikimedia’s Analytic API.
Note
What is an API? A web API (Application Programming Interface) is a set of rules and protocols that allows different software applications to communicate with each other over the internet. A popular form of a web API for data scientists is one that allows applications to access data stored in a database or other data source over the internet. It provides endpoints through which users can send requests to retrieve certain data. For example, a weather data API lets applications request current weather information and forecasts from a weather service’s database.
Note
Everyday data science ethics: Is data collection from APIs a good thing? Using web data APIs is generally considered better from a data ethics perspective compared to crawling or scraping data from the web for several reasons:
Consent and Permission: APIs are like an open invitation. When you use them, you’re playing by the data provider’s rules and getting the data with their blessing.
Data Accuracy and Integrity: APIs give you clean, structured data, which means fewer mistakes and more reliable info. No need to worry about messy data or errors creeping in.
Respect for Resources: Scraping can hammer a website’s server and mess things up for other users. APIs are built for automated access and can handle your requests without causing a fuss.
Privacy and Security: APIs often require you to log in and prove you have permission to access the data. This keeps private info secure and makes sure only the right people see it.
Legal Compliance: Using APIs makes it more likely that you are on the right side of the law. You’re following the provider’s terms of service, so you’re less likely to run into legal trouble for things like copyright issues or unauthorized data use.
All that being said, using an API does not automatically make your data collection ethical. You still need to consider the data provider’s terms of service, privacy policies, and any other ethical considerations that apply to the data you’re collecting.
Gathering Wikipedia Pageviews to measure public attention
The code chunks below demonstrates how to collect and graphically display pageviews data using the Wikimedia Analytic API. Usually, in order to access data from an API, the user has to engage with the documentation to figure out how the endpoints work, under which condition and how the data can be used, etc. In our case, interaction with the API using the R software has been made straightforward with a dedicated R client. That client is provided via the pageviews package.
With the command article_pageviews()from that package, we can now gather pageviews of any article on specific Wikipedia projects. Let’s use it to settle once and for all who’s the most popular classic philosopher! We will restrict ourselves to the English Wikipedia project (en.wikipedia) and to three philosopher superstars, namely Socrates, Plato, and Aristotle. e also specify the argument user_type = "user", which ensures that we exclude pageviews generated by bots and spiders. Finally, start and end define the period on which we want to collect pageviews data: January 2020 to June 2024.
# get pageviewsphilosophers_views<-article_pageviews( project ="en.wikipedia", article =c("Socrates", "Plato", "Aristotle"), user_type ="user", start ="2020010100", end ="2024063000")# overviewhead(philosophers_views)
project language article access agent granularity date views
1 wikipedia en Socrates all-access user daily 2020-01-01 3527
2 wikipedia en Socrates all-access user daily 2020-01-02 4037
3 wikipedia en Socrates all-access user daily 2020-01-03 3891
4 wikipedia en Socrates all-access user daily 2020-01-04 4073
5 wikipedia en Socrates all-access user daily 2020-01-05 3740
6 wikipedia en Socrates all-access user daily 2020-01-06 4266
Now, let’s get a brief overview of the relative popularity of our philosophers taking the average pageviews over the entire period as benchmark.
# average pageviews by philosopherphilosophers_views%>%group_by(article)%>%summarise(mean_views =mean(views, na.rm =TRUE), median_views =median(views, na.rm =TRUE))%>%arrange(desc(mean_views))
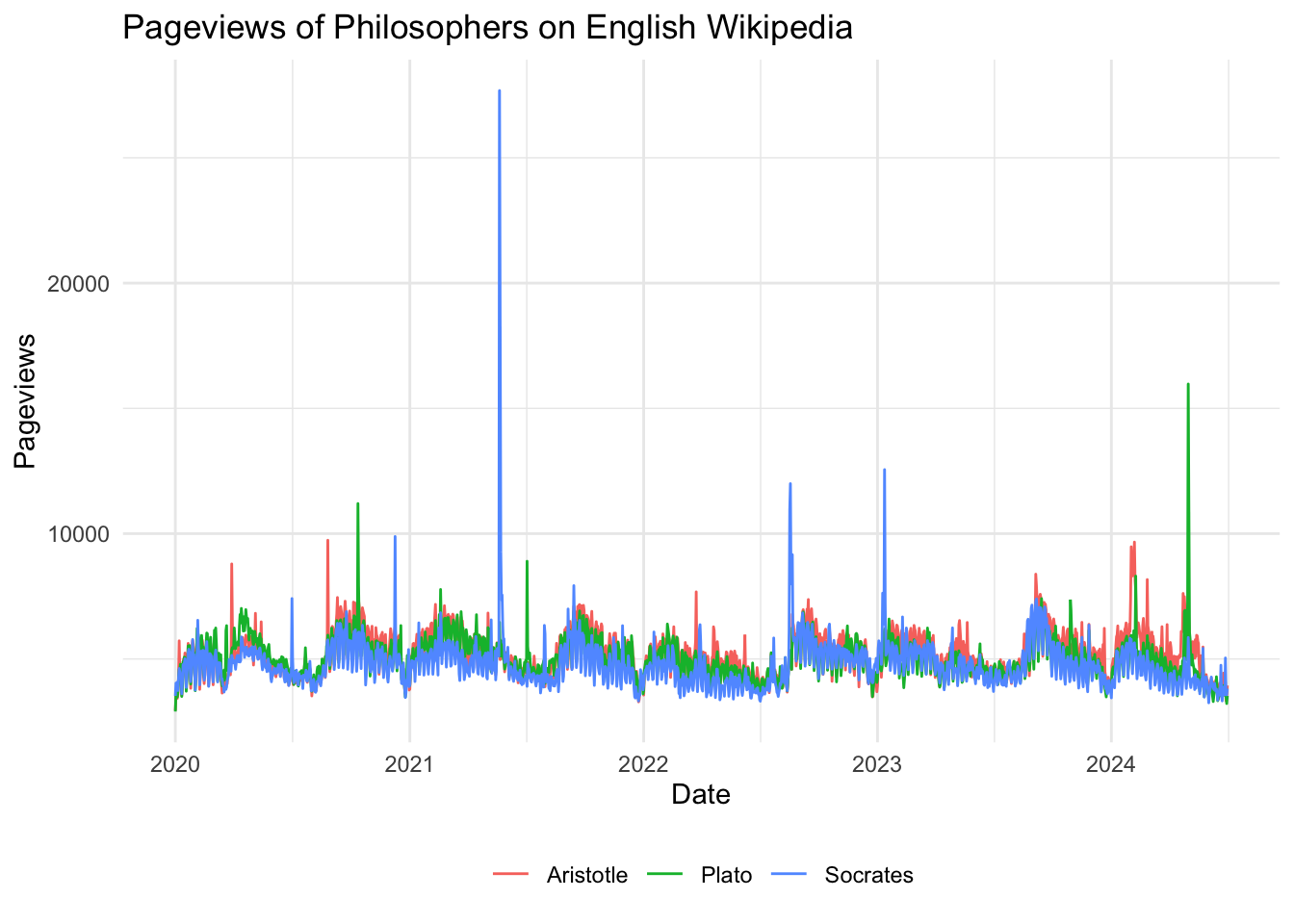
And the winner is… Aristotle! He is the most popular philosopher among the three (both in terms of mean and median), followed by Plato and Socrates. However, the differences are not large, and all three philosophers are still very popular on Wikipedia, garnering roughly 5,000 views per day on average.
Finally, we can also plot the frequencies of pageviews over time to identify trends in search behavior. As we can see, there are some ups and downs and some notable spikes, but the overall trend is quite stable over time.
# Plot pageviewsggplot(philosophers_views, aes(x =date, y =views, color =article))+geom_line()+labs(title ="Pageviews of Philosophers on English Wikipedia", x ="Date", y ="Pageviews")+theme_minimal()+theme(legend.position ="bottom", legend.title =element_blank())
Conclusion
Collecting and analyzing Wikipedia data is straightforward and completely free. This allows researchers to utilize and examine a vast amount of data, providing valuable insights to human knowledge production and consumption. Social science research is increasingly incorporating these advancements, as seen in recent studies (e.g., Göbel and Munzert 2018; Shi et al. 2019).
Note
Everyday data science ethics: Is it OK to work with Wikipedia data? When using data from Wikipedia, it is important to consider the ethical implications of data collection and analysis. Wikipedia is a collaborative platform that relies on the voluntary contributions of its users. As such, it is essential to respect the terms of use and licensing agreements when using Wikipedia data for research purposes. Researchers should also be mindful of the potential biases and inaccuracies that may be present in Wikipedia data. Since entries can be read and edited by both humans and machines, the accuracy of content and validity of metadata are not guaranteed. Researchers should also consider that Wikipedia data relies heavily on user-driven content creation, editing, and usage. This reliance can lead to systematic selection bias and issues with data equivalence (e.g., articles on historical political figures may receive fewer views and edits than those on active politicians, for reasons unrelated to their actual significance). These caveats are not unique to Wikipedia data; they highlight the general necessity of thoroughly scrutinizing and critically assessing the suitability of any data for addressing substantive research questions.
References
Note
Learn more: Denis Cohen, Nick Baumann, Simon Munzert (2019, August 26). Studying Politics on and with Wikipedia. MZES Methods Bites. URL